At Edgescale, we’re engineering the infrastructure that brings artificial intelligence into the real world. Our work powers AI in the places that keep society running — manufacturing floors, hospitals, utilities, transportation networks, and more. By bridging the gap between the cloud and the physical edge, we enable real-time intelligence where humans and machines work together.
In this post, we’ll be diving deep on the unique challenges of deploying AI in environments that are distributed, restricted, segmented, and often disconnected.
An industrial AI team we know of was recently given one shot per week to update a model running across hundreds of sites. A single weekly update window. A forest of custom integration hoops to jump through. A rollback story that involved dispatching a technician. The engineers hated the project. The team’s DORA metrics — the numbers their leadership used to gauge whether they were shipping well — were blown past any reasonable threshold. They nearly walked away from the customer.
The reflexive diagnosis is “bad infrastructure, a better network will fix it.” It won’t. That “one shot per week” complaint is a symptom of a control-plane architecture mismatch, not a networking one. The fix isn’t to ship faster over a thin link. It’s to redraw where the control plane lives. When you do, Day 2 stops being “we can only touch it once a week” and becomes something very different: we touch it continuously in the twin, and the fleet converges on our cadence, not the network’s.
If your Physical AI program is living with weekly update windows and manual rollbacks, this post is for you.
Why DevOps breaks at the sovereign edge
Traditional DevOps quietly assumes three things: a central control plane that everyone can reach, constant connectivity between the developer’s laptop and the production node, and a roughly homogeneous fleet of targets. Sovereign AI at the physical edge breaks all three. Sites are DDIL — denied, degraded, intermittent, limited. Hardware profiles vary by customer, regulatory regime, and procurement cycle. Humans visit rarely, and when they do, the cost of every visit is real.
Given those conditions, “doing DevOps at the edge” requires a lot more than just trying to stretch the existing pipeline further. It requires a redistribution of where the control plane lives. You push just enough of the control plane onto the node itself — declaratively, not imperatively — so the node can govern itself between sync windows. And you keep the creative, iterative part of DevOps at the Edgeport — Edgescale’s central integration environment where engineers iterate, sign artifacts, and publish — and where connectivity is a given. Apollo is the connective tissue between the two: the management plane that signs and channels every artifact from the Edgeport down to each Edgescale Cube (Edgescale’s Physical AI appliance). Palantir has a name for this end-to-end orchestration across connected and disconnected environments — autonomous deployment. Here at Edgescale, our Physical AI Infrastructure is what extends the autonomous deployment of AI to the physical world.
Principled Intransigence
The most sophisticated buyers of edge AI are increasingly refusing to take on use cases that don’t allow rapid iteration, A/B testing, deployment, and rollback at the edge. From the outside it can look like principled intransigence. From the inside, it’s a lesson learned the hard way.
Similarly, mature suppliers such as Palantir have walked away from real revenue rather than work in environments where physical-edge realities strangle software discipline.
The signal to the rest of us: at the sovereign edge, the cost of getting Day 2 wrong is not measured in DevOps maturity scores. It is measured in lost deals.
Six principles for Day 2 at the sovereign edge
A distributed, tiered control plane. The blueprint is Apollo’s documented hierarchy of Hub and Spoke Environments, instantiated for the sovereign edge: a root Hub at the Edgeport, regional Hubs at the aggregation tier, and a fleet of Spoke Environments — each one an Edgescale Cube. Each Cube is a first-class Apollo Spoke, not a derivative or a parallel system bolted alongside. The Cube fleet is a citizen of the Palantir ecosystem; Apollo’s published architecture supports the hierarchy directly.
Each tier caches a signed desired-state manifest. Each Cube runs a Spoke Control Plane that continuously polls its Hub for new Plans — Apollo’s documented pull model, conceptually in the same family as Flux or Argo but built for hierarchical, sometimes-disconnected fleets. Plans are gated by Constraints (cross-service dependencies, schema versions, maintenance windows), so they only execute when the Spoke is ready. If the Cube can reach its Hub, it pulls a new state; if not, it keeps enforcing what it knows. “Free-run” at the edge is really “locally-governed by the last signed Module.” That Module carries an expiration, so a Cube cut off for too long falls back to a known safe mode rather than drifting silently into an undesired state.

Figure 1 — Distributed Control Plane. Apollo’s documented hierarchy of Hubs and Spokes, instantiated for the sovereign edge. Signed Modules flow down. Reported State flows up. Local autonomy holds when the link doesn’t.
Signatures replace the pipeline as the unit of trust. Centralized DevOps trusts the pipeline: the container image system built it, so it’s good. At the edge you can’t always verify pipeline identity online when a bundle (module or modules) arrives, so trust has to travel with the artifact. This isn’t a novel position — it’s a published Apollo principle: “a core design principle of Apollo is that the instructions for how a container image is deployed should be versioned and immutable in the same way as the container image itself.” Every Module — every model weight, container, configuration, and policy — is cryptographically signed with full provenance: cosign and sigstore, accompanied by SBOM and attestation. The Spoke verifies the chain locally before any rollout. The pipeline’s trust is baked into the bits.
The twin is the system of record for DevOps velocity. The rapid-iteration part of DevOps — the part that demanding buyers care about — happens in a digital twin at the Edgeport that mirrors the edge stack, where Modules can be signed from. Engineers iterate there at normal velocity. Deployment frequency, lead time, A/B test throughput — all of it lives in the twin. The fleet converges when it can. Signed Modules are the currency between twin and fleet. Lead time is measured from commit to eligible Spoke reconciled, with disconnect time treated as a known, measured latency rather than a failure. That reframe is what actually unblocks the one-shot-per-week pain: you stop measuring velocity by the worst link in the network.
A/B and canary strategies compress at the edge. Classical canary deployment assumes a big fleet of interchangeable nodes — you slice traffic by routing 1% of requests to 1% of the servers. At the sovereign edge you might have one Cube per site, so there is no peer fleet to canary across. The Cube becomes its own canary population. After a new bundle clears signature verification and local health gates in the standby slot, it does not take over all traffic at once. It starts serving a small percentage of requests — say 1% — while the active slot continues to handle the rest. The canary slice is evaluated locally against the incumbent: latency, error rate, output divergence, drift signals. If it holds, the traffic share steps up progressively — 5%, 25%, 50%, 100% — with the health gates re-checked at every step. Only when the new version has been stable at 100% for a defined soak window does the atomic flip make it the new active and demote the prior bundle to last-known-good standby. Any regression along the way snaps traffic back to the active slot and aborts the new bundle. No upstream call required, no all-or-nothing flip at the moment of promotion.
Rollback is local and automatic — and composes with fleet-level Recall. Dual-partition, A/B slot updates: active and standby. This is the Tesla and ChromeOS pattern applied to industrial AI. If a new deployment fails local health gates, the Spoke flips to standby without human intervention and without phoning home. That’s what actually bounds MTTR when connectivity is intermittent — recovery doesn’t wait for a ticket, a human, or a round-trip to the Edgeport.
Apollo handles the other half of the rollback story at the fleet level. Its Recall subsystem withdraws a Release across the fleet with configurable roll-off strategies. The two layers compose: a bad Module that slipped past local health gates can be Recalled centrally; a bad Module caught at a single Cube can be rolled back locally without bothering the rest of the fleet. A/B slot is the Edgescale contribution below Apollo; Recall is the Apollo contribution above it. Together, the rollback story spans the device and the fleet without seams.
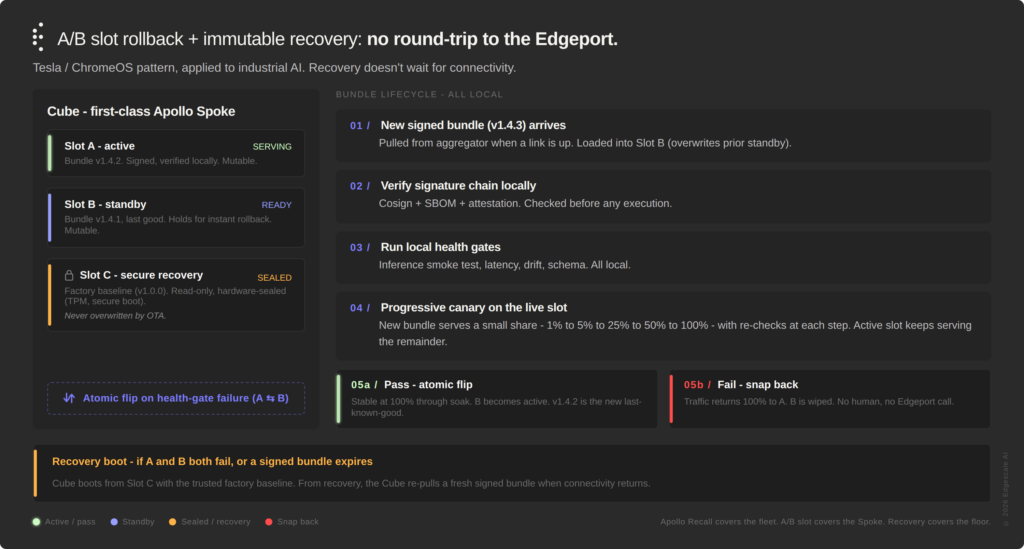
Figure 2 — A/B Slot Rollback. The Tesla / ChromeOS pattern, layered beneath Apollo’s Spoke Control Plane. MTTR is local flip time, not ticket-to-fix time.
Store-and-forward observability; drift as a first-class SLO. Logs, metrics, and traces land in a local ring buffer and batch-upload as Reported State whenever a link appears. Metric cardinality is disciplined locally so the buffer doesn’t explode under sustained disconnect — this is the trap people often fall into. Drift is tracked as explicit SLOs: time since last successful sync, age of the current policy Module, model divergence from the fleet baseline. On reconnect, merge rules are explicit rather than last-writer-wins: Edgeport-defined desired state wins for policy; the Cube’s Reported State is append-only and merged; edge-observed feedback queues centrally, but doesn’t auto-apply. That’s the critical plumbing that prevents a long-split Spoke from quietly corrupting the system of record.
Eight lessons from continent-scale Physical AI — and how the Edgescale Cube embodies each
All of the principles above aren’t theoretical – they match what the Edgescale and Palantir teams have distilled from continent-scale deployments of Physical AI. And throughout those global deployments, we have compiled eight lessons, each with its own one-word shorthand, and each with a direct mapping to how the Edgescale Cube implements them.
01 — Apollo. Rapid deploy and iteration is harder and more necessary. Everything in your environment conspires to slow iteration down, but the stakes of being wrong are higher because models touch physical operations. The Cube answers this with Apollo Release Channels — the Staging → Pre-prod → Fleet pipeline is a custom set Edgescale runs on top of Apollo’s documented defaults (DEV, RELEASE_CANDIDATE, RELEASE), tuned for sovereign-edge operation. Modules are signed in the twin, promoted through Channels by Plan-and-Constraint evaluation, and pulled by each Cube via continuous poll. Each Cube is a first-class Apollo Spoke; the Cube fleet is a fleet of Spokes — not a parallel system, not a derivative. Cubes reconcile; they aren’t pushed to.
02 — Virtual Connected Edge (VCE). Connectivity is usually an afterthought, yet it makes or breaks success. Most edge platforms treat the network as a property of the datacenter rather than a design constraint. The Cube’s Virtual Connected Edge (VCE) pattern inverts that. Each Cube is self-contained — local compute, storage, routing, the ESSF encrypted egress-only SDN, multi-access WAN — so it can function as an operations node regardless of link state. There is a critical caveat we return to in the next section: VCE is the starting condition, not the finish line. Every layer above it is built assuming the VCE can be offline.
03 — Manifold. Critical interfaces need anti-corruption layers. OT systems, sensor buses, plant historians, legacy PLCs — each speaks its own dialect, and piping them straight into AI infrastructure creates brittle coupling that shatters the next time the plant upgrades a controller. Edgescale’s Data Manifold sits between them as an anti-corruption layer: it normalizes, governs, and shields the inference runtime from source idiosyncrasies. Because Data Manifold holds ontology and operational state locally, inference keeps running even when the link to Foundry is cold.
04 — Auto-restore. Design-for-failure beats variable control for resilience. You can’t monitor your way out of failure at fleet scale; you have to design so failures self-correct. Apollo’s own design endorses the bootstrap-from-zero pattern — the helm-chart-operator that anchors every Spoke Control Plane takes no dependencies on other services and is the first thing installed. The Cube extends that principle one layer down: an immutable RHCOS base supporting dual-partition OS updates and a self-bootstrapping safe mode that holds even when the rest of the system has been wiped. Health gates run locally. If a new Module fails them, the Cube flips to standby on its own, extending the capabilities of Apollo. Signed Modules expire; a long-split Cube falls back to safe mode rather than drifting. All of it local, all of it automatic, none of it waiting on Edgeport.
05 — Chaos. Continuous verification across the full stack is non-negotiable. In the cloud, chaos engineering is a maturity signal. At the edge, it’s the price of entry. The Cube runs continuous verification harnesses locally — against model behavior, data integrity, drift, and rollback readiness — and results are stored and forwarded to Edgeport via streaming, when the cube is online.
The decisions get made by Samantha, an agent-based SRE that lives on every Cube. Samantha operates in two modes. In her primary mode, she is the steady-state SRE: she monitors state metrics, watches the system after the Module has landed, and takes corrective action — quarantine, flip, alert — when verification fails. Samantha is not Apollo’s deployment agent. Apollo’s helm-chart-operator and other Spoke-Control-Plane agents handle the deployment-time work of executing Plans and reporting state; Samantha runs alongside them, on the same Cube, but at a different layer. When something regresses, she acts locally before Edgeport even sees the signal, because the signal might not make it upstream in time. She compresses telemetry, triages incidents, and reasons about local state in ways that a per-Cube human SRE never could at fleet scale.
In her second mode, Samantha is the Cube’s in-house chaos agent. She actively probes the boundaries of the system as a whole — injecting noise into inputs, perturbing latency, simulating partial failures, stressing fallback and rollback paths — to surface issues, vulnerabilities, and latent failure modes before they appear in real traffic. The guardrail is firm: Samantha is allowed to inject noise that may disrupt the system, but not destroy it. Before running any chaos experiment, she evaluates it against a pre-flight check; if a given inference is determined capable of taking the Cube down, Samantha does not execute. Instead she reports the proposed experiment, with full context, up to human operators — alongside the steady-state telemetry her SRE persona is already streaming. Findings from sanctioned chaos runs feed back into the local verification harnesses as new gates.
Agentic SRE isn’t a futurism story at the sovereign edge; it’s the only way to operate when the link is the variable.
06 — M-for-N. Parallel full-stack staging paths — more than you think. You can’t stage sovereign,Physical AI on a single linear pipeline. M customer contexts × N hardware SKUs × K regulatory envelopes produces a lot of paths, each producing signed Modules for its own fleet of Spokes. Apollo’s Release Channel architecture lets you fan out without collapsing governance. Apollo’s RBAC even supports a Restricted Contributor role — promote only the Releases you own — so multiple staging paths can share an Edgeport without stepping on each other. Because Modules are signed and immutable, you can stage in the twin, promote through pre-prod, and release to fleet with confidence that each Cube will verify locally regardless of whether it was online when the Module arrived.
07 — Enterprise-grade. Ecosystem leverage always wins. The attempt to build every layer in-house is the reason most Physical AI projects get stuck in pilot purgatory for 18-24 months before ultimately failing. The Cube is purpose-built on a robust set of core-stack partner technologies including RHEL CoreOS, OpenShift, Apollo, Palantir Foundry and AIP, NVIDIA Blackwell, and 200+ data connectors. The result is full-stack Physical AI solution made of fungible, ecosystem-standard parts. That’s what makes it shippable and operable by even the leanest of IT organizations, and it’s what keeps the stack supportable across a six-year industrial procurement cycle.
08 — Declare, admit, sign. Principles applied everywhere consistently. This is the meta-lesson, and the one that’s hardest to hold. Declare the desired state. Admit what actually runs (audit logs, inventory, drift reports). Sign every artifact and every claim. Applied everywhere, consistently, you get a fleet that is governable at continent scale. Applied partially, you get the drift that brought you the one-shot-per-week project in the first place. Apollo bakes this in at the platform layer. Releases are scanned and gated as part of Channel promotion. Sign, scan, gate is applied everywhere, not just where convenient. The Cube enforces declare-admit-sign locally even when offline; the signed Module carries its own verification criteria, so the Cube can attest to its own state and queue the attestation for the next time a link opens.
Connectivity realism: what VCE doesn’t solve by itself
It’s tempting, once you have a VCE design and an encrypted egress channel, to assume the connectivity problem is solved. It isn’t.
This isn’t about the WAN technology. Diverse 10G fiber, LEO satellite, and 5G are all available, mature, and increasingly affordable. The connectivity problem at the sovereign edge isn’t bandwidth — it’s how a Cube integrates with the enterprise network where the data actually lives. Plant networks are distributed by site, restricted by policy, and segmented by design. They are hostile to outbound traffic for sound security and OT reasons; ESSF helps, but it doesn’t override that operational reality. Even where the WAN is adequate in aggregate, the in-line behavior is unpredictable — customers reboot edge firewalls, rotate certs, and shut links during maintenance windows without telling anyone.
That forces a specific set of design choices into the architecture. Assume offline as the normal state; online is a window of opportunity. Every pull is opportunistic; every push is fire-and-forget-with-retry. Local authority is the default, always. A Cube must be fully governable by its last-known-good signed Module, and operations do not stop when the link does. Metric cardinality is disciplined locally so the store-and-forward buffer doesn’t explode under sustained disconnect. And merge semantics on reconnect are explicit rather than last-writer-wins: Edgeport-defined desired state wins for policy; the Spoke’s Reported State is append-only and merged; edge-observed feedback queues centrally but doesn’t auto-apply.
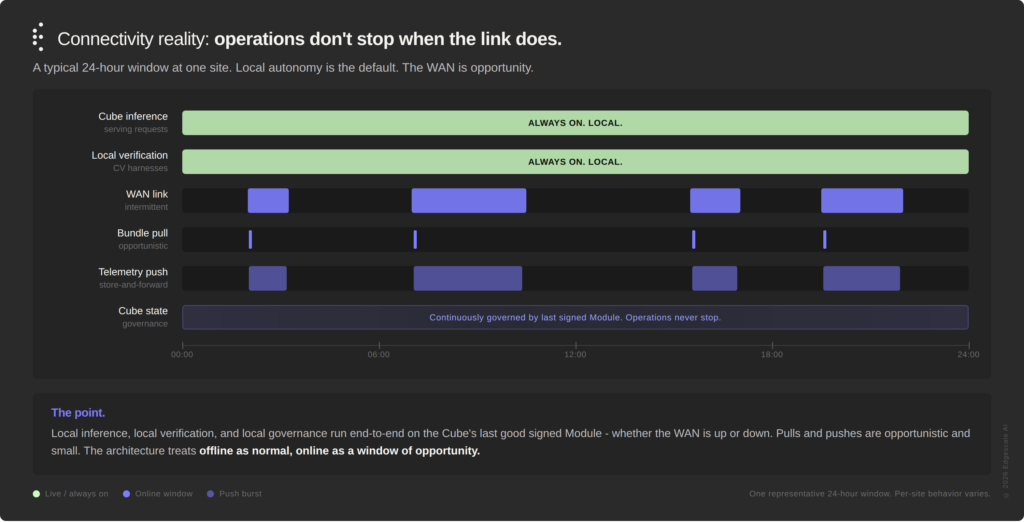
Figure 3 — Connectivity Reality. Local inference, local verification, and local governance run end-to-end whether the WAN is up or down. Pulls and pushes are opportunistic and small.
A lesson to keep in mind: ESSF is the channel; the distributed control plane is the architecture. You need both, and they aren’t the same thing. VCE doesn’t save you by itself — architecture does. That’s the difference between a deployable Sovereign AI platform and a demo that works only when the network cooperates.
DORA reframed for the sovereign edge
DORA metrics — deployment frequency, lead time for changes, change failure rate, and mean time to restore — come from the DevOps Research and Assessment program (originally independent, now at Google) and have become the standard vocabulary for measuring software delivery performance. They’re what most engineering leaders ask their teams to move, and they’re exactly what gets blown apart by naive edge architectures.
Here’s how they survive at the sovereign edge when you build it right:
- Deployment frequency = signed-Module publication cadence into the twin.
- Lead time = commit to eligible Cube reconciled, with disconnect time treated as measured latency rather than failure.
- Change failure rate = local health-gate failure rate × fleet exposure, bounded by auto-restore and Apollo Recall.
- MTTR = local flip time, not ticket-to-fix time.
You don’t abandon DevOps rigor at the sovereign edge. You redefine it. The eight lessons above are what make that redefinition work. If your DORA numbers look bad at the edge, that’s evidence of a control-plane architecture problem — not a DevOps maturity problem. And it’s an architecture problem you can solve.
What’s next
In a future post we will be walking through the full reference architecture, including: Apollo’s hierarchy of Hubs and Spokes instantiated for the sovereign edge; the Edgeport twin environment; the Cube fleet as first-class Spokes; signed-Module lifecycle; Plan-and-Constraint evaluation; Recall and roll-off strategies; explicit connectivity degradation modes. Stay tuned, or subscribe to our blog for updates.
And if your Physical AI program is living with weekly update windows, manual rollbacks, or outages that trace back to bad assumptions about connectivity, we’d like to compare notes. The teams doing this well aren’t doing it because they got lucky with the network. They’re doing it because they redrew the control plane. We’ve done the work, and we’re here to help.