At Edgescale, we’re engineering the infrastructure that brings artificial intelligence into the real world. Our work powers AI in the places that keep society running — manufacturing floors, hospitals, utilities, transportation networks, and more. By bridging the gap between the cloud and the physical edge, we enable real-time intelligence where humans and machines work together.
Introduction
In the wake of Generative AI (GenAI) and the Internet of Things (IoT), technology in the world around us is changing faster than ever before: we use large language models (LLMs) to automate tasks, we ride in autonomous vehicles, and we direct scores of connected devices by voice.
As a result, software that powers this technology is placing new, exponential demands on cloud and network infrastructure. In this post, we discuss the imperative to consider infrastructure as a key enabler for speed and differentiation, some historical and rising options, and our novel approach to tap infrastructure resources beyond the traditional cloud. Lastly, we explore a practical example to improve product performance and efficiency.
Competitive necessity
“He who controls the H100s, controls the universe.”
In a popular meme, referring to Frank Hubert’s novel, Dune, access to graphics processing units (GPUs) rather than the resource ‘spice’ now determines the destiny of software companies. Given the explosive demandand volumes of GPUs required to train LLMs, dominated by Meta, OpenAI, Anthropic, xAI, among others, there is truth in this for some companies. And, it is likely to be true for some time as AI-based software scales up, given that the demand for inference is expected to dwarf the demand for training.
More broadly, this points to the systemic truth that infrastructure to run software (i.e. cloud compute) and infrastructure to transport data (i.e. network connectivity) are strategic imperatives for companies delivering software-as-a-service (SaaS). Doubly so when software is paired with streaming data and dispersed physical devices.
This is already a core tenet of the SaaS value proposition: with infrastructure comes the power to differentiate and deliver capability faster to customers. While the implications can be acutely seen today in the case of GPUs to create viable products, they commonly manifest as product reliability and quality of experience: with the right placement of infrastructure, one service is responsive to vast numbers of users, while another service topples over. A further example is the recent rise of sovereign clouds, where appropriate infrastructure can enable (or disable) access to certain customers and markets. Lastly, as infrastructure cost is tightly linked to product margin, it inevitably drives value creation at the same time.
In short, having the right resources at the right place matters. Increasingly, access to the leading infrastructure is a necessity for companies seeking to outcompete and deliver services at scale.
Where no cloud has gone before
While the benefits of cloud computing are well known, in giving rise to the SaaS paradigm, what happens when software seeks functionality beyond the capabilities of the cloud? When expansive banks of compute are needed for heavy-duty workloads and/or the economics of high-powered compute and egress break down? Or huge volumes of data and customers encounter severe network bandwidth constraints between the cloud and the users?
Historically, industry-leading companies embrace a hybrid model to optimize flexibility, cost, and performance. Netflix and Meta, for example, invested heavily in building distributed hybrid compute-and-networking platforms (Hybrids, as we call them) with Open Connect and and Edge Fabric, respectively. By building beyond the cloud, on-premise, into the edge and telecom networks, they reduce their costs and extend their applications close to their users to avoid network-induced impairments to their service. In other words by building beyond the cloud, they use infrastructure to boldly differentiate their service and optimize their margin.
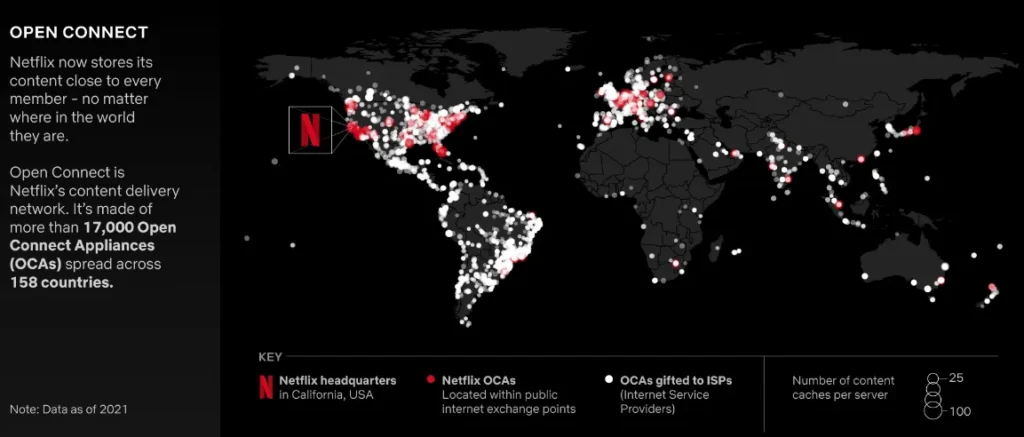
Building Hybrids is also extremely time-consuming and expensive to do, typically requiring entire teams of network engineers and hardware specialists; which is why SaaS companies are often locked in the cloud and these infrastructure powers are limited to the most profitable, savvy and/or very brave companies. Yet, there is work being done to simplify hybrid management and growing sentiment that the performance benefits of distributed applications and economic benefits of repatriation to Hybrid models are becoming too alluring to ignore.
Fortunately for companies leading the next wave of software there are more infrastructure options than ever. The telecommunications, data center, and silicon ecosystem, aware that demand is spiking and an impending cost-per-compute-per-watt crisis is looming, are making massive long-term investments. Leaders, like Nvidia and Broadcom, and a wide range of new entrants, like Groq and Cerebras, are delivering optimized chipsets and network accelerators which promise orders of magnitude improvements. Traditional data centers are building new facilities in droves with efficient cooling and renewable energy and are offering high performance, low-cost bare-metal as-a-service. Cloud service providers (CSPs) are expanding their offerings while boutique clouds are emerging. Communication service providers (also CSPs, confusingly) are building higher-bandwidth 5G networks, offering now useful satellite-overlay with new constellations, and are dabbling in network-attached compute offerings (i.e. MEC, multi-access edge compute).
Also unfortunately there are more options than ever, and more volatility. Where should we invest our DevOps team’s focus? How do we get access to the latest chips, and 5G and satellite networks, when new ones are coming online every year? If it’s so time-consuming and the options are changing so quickly, is it worth it? The perception of complexity and cost, coupled with volatility, means most SaaS companies have not ventured beyond the cloud despite the obvious gains and growing necessity.
We’re going to change that.
Expanding the cloud universe
As software becomes more capable through AI, it demands more from infrastructure and more data. At the same time we develop new models and virtualize more systems, we have to evolve how we use infrastructure to scale them. This is the aim of Edgescale AI: to help software companies use diverse global compute and connectivity infrastructure and distribute software to the people and devices interacting with it.
We take a systematic and combinatorial approach to digital infrastructure. Why should we be restricted to one, or a few options? Can’t we select all, and chose what is appropriate at the time? Roughly analogous to a virtual machine (VM) abstracting hardware resources, or a virtual private cloud (VPC) grouping resources within a cloud, we’re taking the next step, to combine and abstract many compute and network providers into what we call Virtual Connected Edges (VCEs).
VCEs are an ambitious construct: a composable multi-cloud, multi-network environment to run cloud-native software, distributed to where its needed, at global scale. VCEs are inspired by our recent work, building one of the largest and most performant Hybrids ever conceived and prior work, delivering global-scale mobile and satellite networks. These experiences, coupled with the prevalence of virtualization, the maturation of cloud-native tools, and the rise of new networks and compute providers, as discussed above, now make VCEs practical to implement.
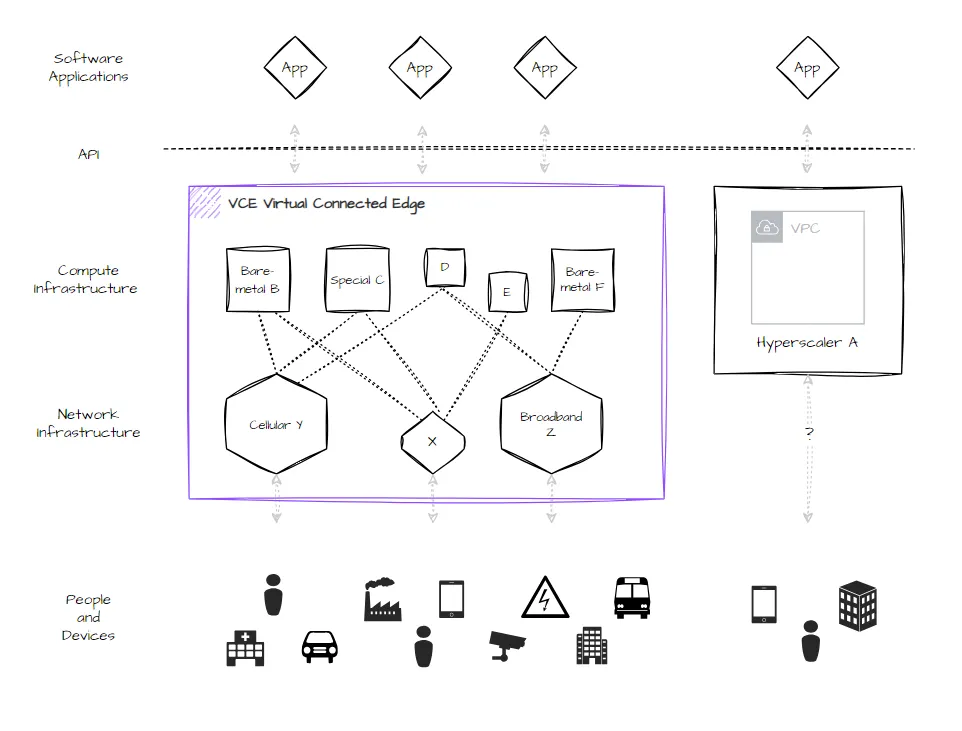
Our software automates the creation of VCEs by setting up and managing consistent virtualization and networking across diverse providers. We apply a series of strict principles and opinionated approaches to securely deploy applications and manage data flow. At the same time, a management plane performs orchestration, observation, and testing functions to deliver an autonomously managed environment and ensure integrity across the supporting components.
VCEs are used by software companies to tap into a variety of providers, inclusive of and beyond traditional cloud. Rather than requiring expertise and effort required to individually select, negotiate with, and customize against various bare-metal or network providers, these infrastructure capabilities are readily consumed by software development teams. Anyone familiar with a typical cloud environment is at ease deploying software to specialized compute and managing data flow over sophisticated telecom networks via a VCE.
Perhaps more significantly, VCEs allow product and software teams to experiment and enhance the performance of their applications more easily. While commonly thought about in terms of latency, distribution of applications — bringing the software to the user, rather than the data to the software — also results in more consistent interactions, smaller blast/experimentation radii, and richer experiences; especially when the volumes of data are large (e.g. as in the case of inference on streaming logs or video).
In sum, as a result of their unique attributes VCEs tend to result in:
- Access to the lowest cost compute, storage and and networking providers
- Latest and fastest capabilities beyond the baseline of the cloud
- High-performance data flow between software and users or devices
- Low effort to iterate and add new capabilities
- Faster deployment and scaling, relative to custom Hybrids
Short circuit
Let’s look at one example how companies use distributed infrastructure to improve their applications. Many use cases today rely on streaming video from cameras (and other sensor modalities), for example fault detection, quality monitoring, and resource management. Site security and safety monitoring is a prevalent and growing application for both consumer and industrial use.
As shown here, the typical architecture calls for a camera to be remotely installed (often with local storage and motion/object capabilities to reduce data volume), third-party network(s) to transport the video stream as needed, and a cloud-based software which performs inference, stores, re-streams, and/or performs closed-loop control functions.
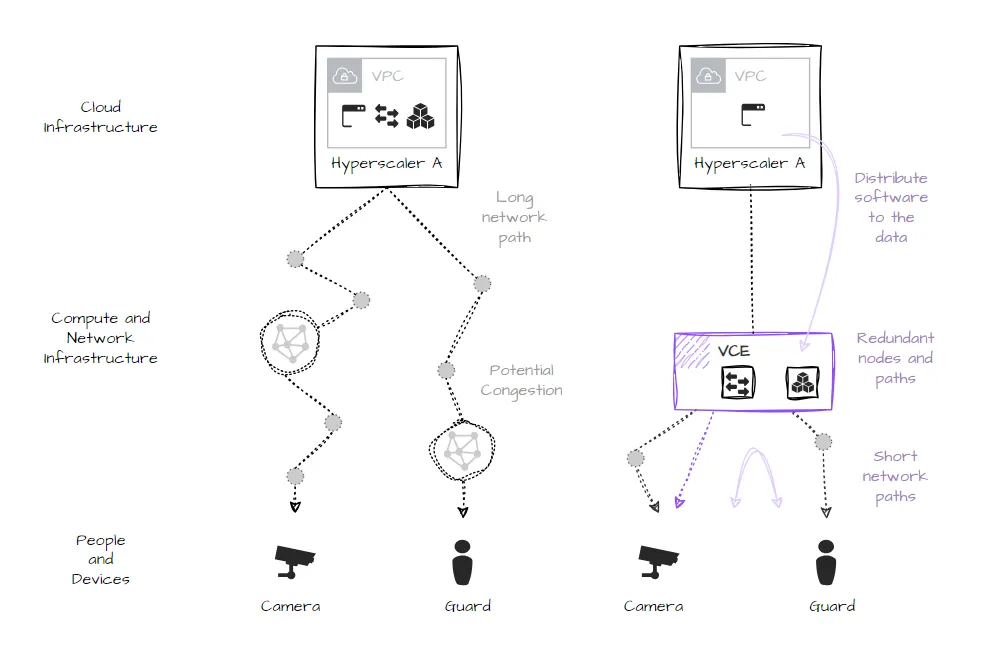
Streaming video is a relatively high volume flow of data over networks and is subject to network congestion, route optimization, de-prioritization, and topological variation: in other words performance depends on the actual path taken. In most cases traffic is handled by several networks to reach the intended destination, each having their own conditions and introducing their own variations which are constantly changing. Despite a security guard receiving an alert and monitoring an event occurring a few miles away, the network path may be thousands of miles. Sometimes it works well, sometimes it doesn’t.
In contrast, running software at optimal places between source and destination is more efficient and creates a reliable, direct path. In many cases, local compute resources and alternate network paths are already therewhich could be used to short circuit the path and deliver a better software and streaming experience.
The challenge, as discussed above, is the difficulty to access these compute resources and network paths. Since cameras can be placed anywhere in the world, with widely different network access relative to widely different compute infrastructure, optimizing software across so many permutations has been untenable for most use cases. VCEs aim to overcome this difficulty with automation and abstraction: to run software where (or in optimal places relative to where) people and devices are, without the legwork.
While we describe one typical scenario here, many applications benefit from a similar approach, especially if they:
- Interact with a large volume of devices/users, over a large area
- Need high volumes of always-on compute
- Work with bandwidth-intensive data streams
Conclusion and future
In this post, we discussed the increasing need for software to differentiate with infrastructure, the increasing number of options available outside the traditional cloud, and a new approach to infrastructure aggregation and abstraction we call VCEs — Virtual Connected Edges.
Our vision for Edgescale AI is to help companies enhance delivery of their software to people and devices interacting with it in the ‘real world’. We do this with VCEs to allow companies of all size and stage (not only the mega-profitable, savvy, or brave) to optimally use a broader variety of compute and connectivity. With our customers to date, we’ve seen this translate to:
- Consistent and superior performance
- Personalization of applications to end customers and devices, or “digital twins”
- Greater scalability to large number of users/devices
- Optimization of cost and obviation of investment
- Flexibility to use and access to the latest advancements in infrastructure
In future posts, we anticipate detailing some of the unique infrastructure layer technologies used to automate VCEs, sharing anecdotes of the perils of venturing beyond the cloud, and delving further into the success stories we see as AI-based software runs closer to and interacts more directly with physical systems in the ‘real world.’
If you’re working to empower people with AI and intelligent connected devices, and this post sparked some ideas for you, get in touch.